给移动开发团队的AIGC基础知识分享|AIGC创新赛|公司内部分享
可能有人知道,前段时间我带了几位同事参加了智脑杯AIGC创新比赛。关于AIGC,第一次引起大家关注,还要追溯到2022年11月底openai发布基于gpt3.5的chatgpt,我在第一时间就体验了。
直到今天,AIGC产业风起云涌,从最底层的“芯片战争”,到大模型软件基础设施,再到应用层,各种公司都在调整组织架构all in AI。
在说比赛的产品和技术之前,先介绍三个概念。
概念考察
AIGC
AIGC,这是非常中式的表达,对标了 PGC UGC,所以可以理解为,通过AI来创造内容,貌似这个词组现在也被一部分英文世界所接受了。
在前期,主要集中在生成文本和图片,前者的代表是chatgpt和llama2,后者的代表是midjournay和stable diffusion;现在也有生成视频、音频之类的内容。
在前期,生成内容需要输入文本描述,也称为prompt;而现在,大模型公司很多在研究用图片生成图片,图片生成视频,文字生成视频等等。也就是说,输入内容的形式和生成内容的形式可以随意匹配,称为多模态。
Copilot
第二个概念是Copilot,直译是副驾驶,本质是日常工作的辅助工具,就像是配了一个足智多谋的实习生。
比如面向程序员的编程助手github copilot,我知道我们这有一些同事已经在日常工作中用上了免费的同类产品。
这次比赛中出现了AI智能合同审核系统,在人气投票期间差点就超过了我们,后来才知道,那段时间所有人找他们审核合同,都被要求先投票再审核。
Agent
还有一个最近非常火的概念,Agent,是创投圈的热门方向。可以理解为能独自处理工作任务并交付的员工,更加完善可靠的智能体。
举个例子,Github Copilot可以根据你的描述帮你生成代码,可以查找代码BUG,可以添加注释。如果这个工具可以理解用户反馈或者产品需求,在合适的位置生成代码,提交并提测,我觉得这就可以称之为一个编程agent。
当然,目前无论国内还是海外,北京还是硅谷,提出agent概念的和还在验证中的agent有很多,但还没有一个是业界认同的真正可商用的agent。
比赛项目
我们做的项目,本质就是一个提供给xxx的copilot,辅助提升xxxx效率的ai工具。
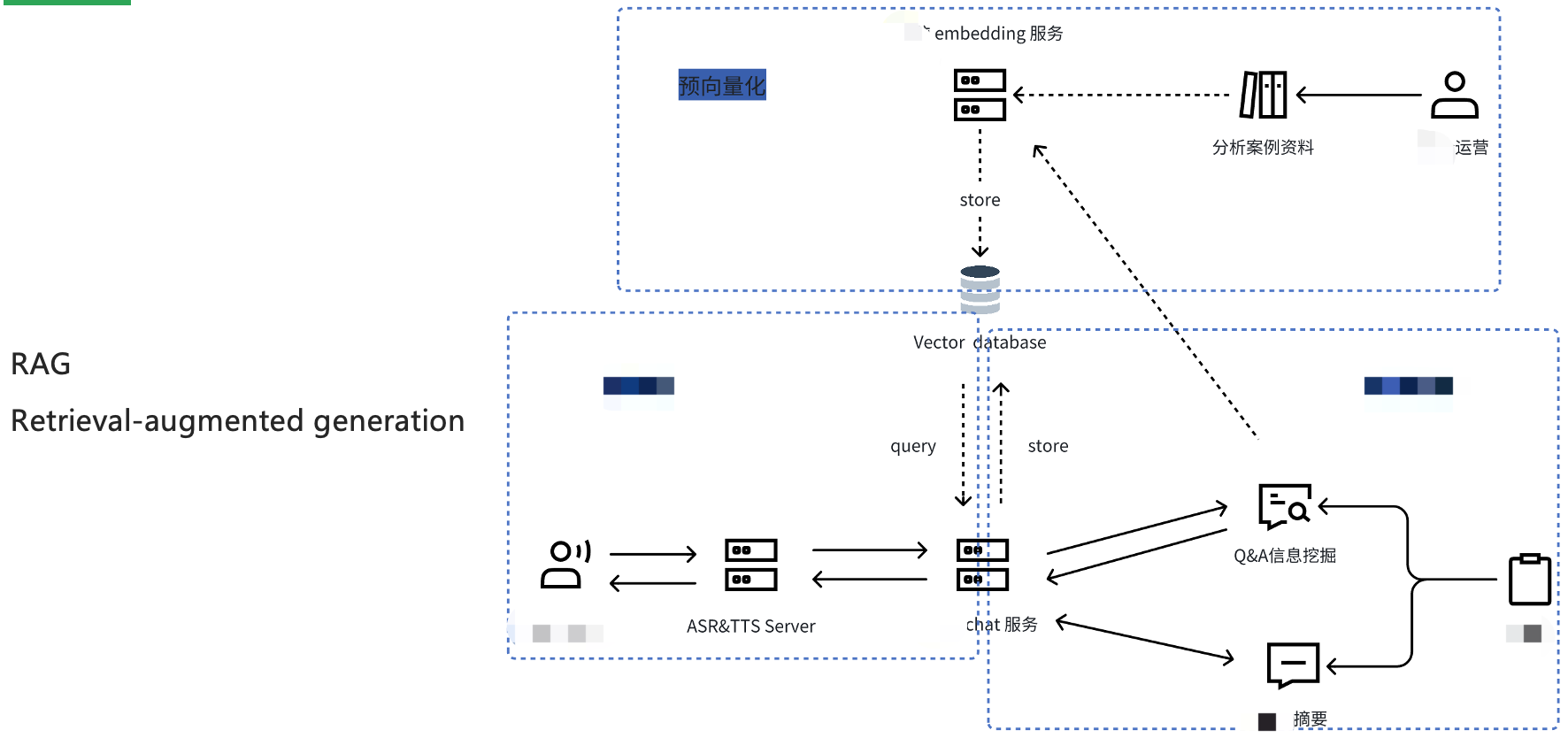
我们的核心技术方案叫RAG。什么是RAG呢?retrieval-augmented generation 检索增强生成技术。什么是检索增强,为什么要用呢?
我们刚说到,目前的AIGC基本都是通过文本作为prompt,但写好prompt就能生成预期的文本吗?
并不能。
没有经过特殊训练的模型,称为基础大模型。可以认为是一个普通的大学生,“知道”很多基础知识、公开的知识,但没有行业经验,没有专业深度。
所以,一些背景信息和知识就需要埋在prompt中,作为推理的核心依据。
我们一开始就是通过手动预埋了很多背景知识,比如xxx,这样,大模型根据这些背景信息和用户输入的动态信息,做出后续的推测。
但是,如果所有的信息都手动填充,就会显得很蠢,RAG方案就应运而生。今年很多创业公司也都做了这种平台,但前段时间的openai devday发布了自己的平台之后,基本都关业大吉了。
这种平台,通常称为知识库。
知识库中,所有提交的文本,可以是txt,或者是pdf,或者其他可提取文本的文件,都会切割成一个个独立的文本单元,通过embedding接口向量化,并存储到向量数据库中。当然,向量数据库也是一个非常重要的创业方向。
通过向量数据库的query接口,查询到与“问题”相关度最高的n个“单元”,作为prompt的背景信息。
毕竟prompt的容量非常有限,把所有的信息都放进去不现实。
这就是RAG的基础逻辑,根据私有知识库完善prompt。据说也有一些公开的知识库可以查询,我还没研究过。

很多法律行业的AIGC产品,还有搜索总结类产品,如BingAI,都是基于RAG技术实现的。
如果了解LLM的进展,会知道 Claude2.1 已经可以进行 200k token 的 input output 了,也就是说,你可以喂给他一本书作为背景信息,那么,RAG还有用吗?
根据我的理解,有两个还需要继续使用的理由,一是使生成更加聚焦,没有无关信息的干扰,输出更加稳定;二是成本成本成本,input output 都是会根据 token 量做结算的。AIGC领域有一个很重要的技术能力,就是如何减少 token 的消耗以降低成本。
我理解更大的 token 处理量,关键是解决了大模型“失忆”的问题。大家知道为什么chatgpt在同一个交互中,越聊天,token消耗越大吗?因为,每次的交互,都会把历史纪录带上去,这就是它的记忆。
回过头来,为什么我们比赛会选择xx这个方向?因为我还是比较了解xx工作的,运营沉淀了大量的xx案例分析资料,都可以作为知识库来使用。
跟刚刚提到的法律行业一样,法律行业的AIGC产品的护城河,也是高质量的私有数据。
Fine tune
最后再提一个概念,fine tune,微调,本质就是在基础大模型基础上做训练,我们为什么不训练模型呢?
有这么几个理由,一,训练模型需要大量优质的语料,我们的资料都是少数运营手写的,未必能达到有效训练的量;二,训练不能增加知识,output的本质是续写,是预测,只能说会增加某些概率,不能作为知识的补充;三,依然是成本,训练的成本可比推测的成本和embedding的成本高很多。
在gpt发展的这一年,很多创业者都感叹,自己购买大量算力和语料微调的模型,在gpt基础模型一次升级之后竟然被完全碾压了。
最后
这就是我今天分享的所有内容,希望对大家有启发。